|
|
||
|---|---|---|
| .vscode | ||
| api | ||
| common | ||
| docs | ||
| gui | ||
| models | ||
| outputs | ||
| .gitignore | ||
| .gitlab-ci.yml | ||
| BENCHMARK.md | ||
| CHANGELOG.md | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| onnx-web.code-workspace | ||
| renovate.json | ||
README.md
ONNX Web
This is a web UI for running ONNX models with GPU acceleration or in software, running locally or on a remote machine.
The API runs on both Linux and Windows and provides access to the major functionality of diffusers,
along with metadata about the available models and accelerators, and the output of previous runs. Hardware acceleration
is supported on both AMD and Nvidia, with a CPU fallback capable of running on laptop-class machines.
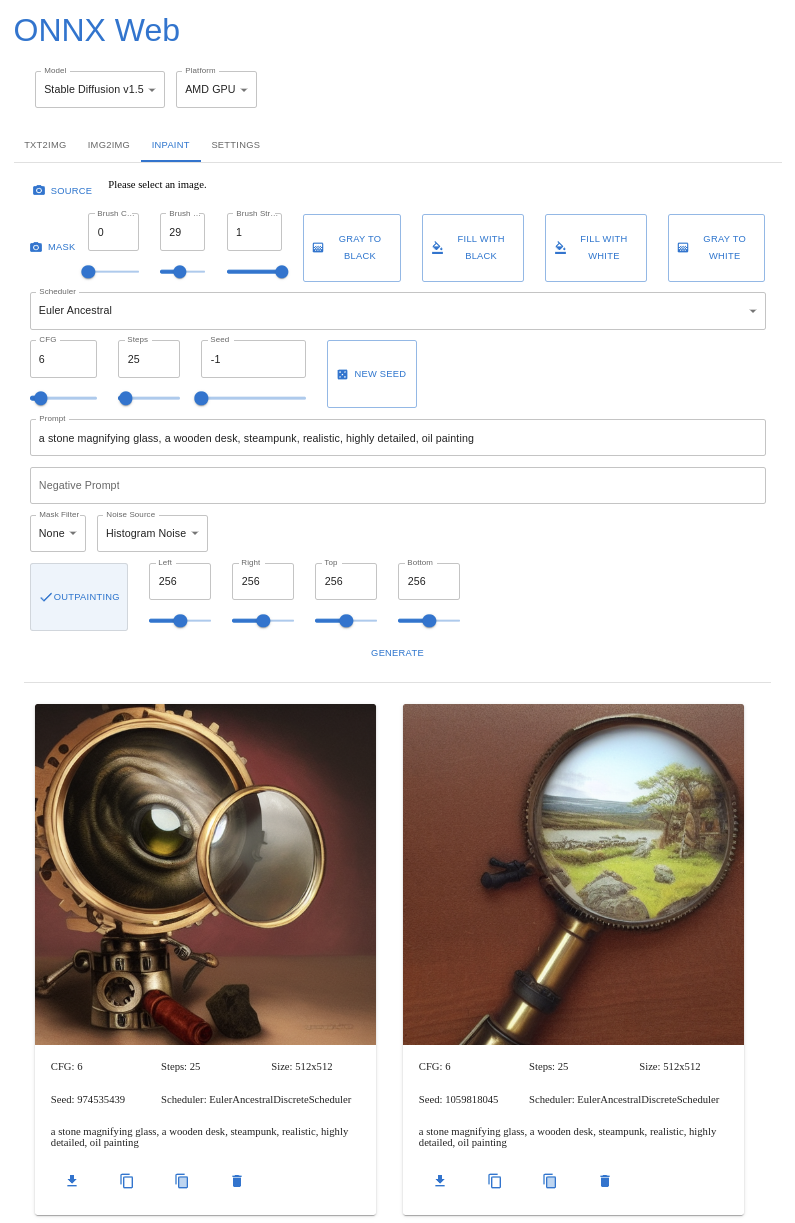
The GUI is hosted on Github Pages and runs in all major browsers, including on mobile devices, and allows you to select the model and accelerator being used. Image parameters are shown for each of the major modes, and you can upload or paint a mask for inpainting and outpainting. The last few output images are shown below the image controls, making it easy to refer back to previous parameters or save an image from earlier.
Based on guides by:
- https://gist.github.com/harishanand95/75f4515e6187a6aa3261af6ac6f61269
- https://gist.github.com/averad/256c507baa3dcc9464203dc14610d674
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
- https://www.travelneil.com/stable-diffusion-updates.html
Features
- REST API server capable of running ONNX models with DirectML acceleration
- AMD and Nvidia hardware acceleration
- CPU software fallback
- multiple schedulers
- web app to generate and view images
- hosted on Github Pages, from your CDN, or locally
- built with React and MUI
- OCI containers
- for both API and GUI
- for each hardware platform
- txt2img mode
- image controls and scheduler selection
- with recent image history
- img2img mode
- image upload with preview
- guided by prompt and negative prompt
- inpainting mode
- mask painting
- source to mask conversion tools
Contents
- ONNX Web
Setup
This is a very similar process to what harishanand95 and averad's gists recommend, split up into a few steps:
- Install Git and Python, if you have not already
- Create a virtual environment
- Install pip packages
- Install common packages
- Install platform-specific packages for your GPU (or CPU)
- Download and convert models
Install Git and Python
Install Git and Python 3.10 for your environment:
The latest version of git should be fine. Python must be 3.10 or earlier, 3.10 seems to work well. If you already have Python installed for another form of Stable Diffusion, that should work, but make sure to verify the version in the next step.
Make sure you have Python 3.10 or earlier:
> python --version
Python 3.10
If your system uses python3 and pip3 for the Python 3.x tools, make sure to adjust the commands shown here.
Once you have those basic packages installed, clone this git repository:
> git clone https://github.com/ssube/onnx-web.git
Note about setup paths
This project contains both Javascript and Python, for the client and server respectively. Make sure you are in the correct directory when working with each part.
Most of these setup commands should be run in the Python environment and the api/ directory:
> cd api
> pwd
/home/ssube/code/github/ssube/onnx-web/api
The Python virtual environment will be created within the api/ directory.
The Javascript client can be built and run within the gui/ directory.
Create a virtual environment
Change into the api/ directory, then create a virtual environment:
> pip install virtualenv
> python -m venv onnx_env
This will contain all of the pip libraries. If you update or reinstall Python, you will need to recreate the virtual environment.
If you receive an error like Error: name 'cmd' is not defined, there may be a bug in the venv module on certain
Debian-based systems. You may need to install venv through apt instead:
> sudo apt install python3-venv # only if you get an error
Every time you start using ONNX web, activate the virtual environment:
# on linux:
> source ./onnx_env/bin/activate
# on windows:
> .\onnx_env\Scripts\Activate.bat
Update pip itself:
> python -m pip install --upgrade pip
Install pip packages
Install the following packages for AI:
> pip install "numpy>=1.20,<1.24"
> pip install "protobuf<4,>=3.20.2"
> pip install accelerate diffusers ftfy onnx onnxruntime spacy scipy transformers
Install the following packages for the API:
> pip install flask flask-cors flask_executor
Or install all of these packages at once using the requirements.txt file:
> pip install -r requirements.txt
At the moment, only numpy and protobuf seem to need a specific version. If you see an error about np.float, make
sure you are not using numpy>=1.24.
This SO question
has more details.
For upscaling and face correction
> pip install basicsr facexlib gfpgan realesrgan
For AMD on Windows: Install ONNX DirectML
If you are running on Windows, install the DirectML ONNX runtime as well:
> pip install onnxruntime-directml --force-reinstall
> pip install "numpy>=1.20,<1.24" # the DirectML package will upgrade numpy to 1.24, which will not work
You can optionally install the latest DirectML ORT nightly package, which may provide a substantial performance increase (on my machine, the stable version takes about 30sec/image vs 9sec/image for the nightly).
Downloads can be found at https://aiinfra.visualstudio.com/PublicPackages/_artifacts/feed/ORT-Nightly. You can install
through pip or download the package file. If you are using Python 3.10, download the cp310 package. For Python 3.9,
download the cp39 package, and so on. Installing with pip will figure out the correct version:
> pip install --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT-Nightly/pypi/simple/ ort-nightly-directml --force-reinstall
Make sure to include the --force-reinstall flag, since it requires some older versions of other packages, and will
overwrite the versions you currently have installed.
For CPU on Linux: Install PyTorch CPU
If you are running with a CPU and no hardware acceleration, install onnxruntime and the CPU version of PyTorch:
> pip install torch --extra-index-url https://download.pytorch.org/whl/cpu
For CPU on Windows: Install PyTorch CPU
If you are running with a CPU and no hardware acceleration, install onnxruntime and the CPU version of PyTorch:
> pip install torch
For Nvidia everywhere: Install PyTorch GPU and ONNX GPU
If you are running with an Nvidia GPU, install onnxruntime-gpu:
> pip install onnxruntime-gpu
> pip install torch --extra-index-url https://download.pytorch.org/whl/cu117
Make sure you have CUDA 11.x installed and that the version of PyTorch matches the version of CUDA (see their documentation for more details).
Download and convert models
Sign up for an account at https://huggingface.co and find the models you want to use. Popular options include:
- https://huggingface.co/runwayml/stable-diffusion-v1-5
- https://huggingface.co/runwayml/stable-diffusion-inpainting
- https://huggingface.co/stabilityai/stable-diffusion-2-1
- https://huggingface.co/stabilityai/stable-diffusion-2-inpainting
You will need at least one of the base models for txt2img and img2img mode. If you want to use inpainting, you will also need one of the inpainting models.
Log into the HuggingFace CLI:
# on linux:
> huggingface-cli login
# on windows:
> huggingface-cli.exe login
Issue an API token from https://huggingface.co/settings/tokens, naming it something memorable like onnx-web, and then
paste it into the prompt.
Download the conversion script from the huggingface/diffusers repository to the root of this project:
Run the conversion script with your desired model(s):
# on linux:
> python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="runwayml/stable-diffusion-v1-5" --output_path="./models/stable-diffusion-onnx-v1-5"
# on windows:
> python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="runwayml/stable-diffusion-v1-5" --output_path=".\models\stable-diffusion-onnx-v1-5"
This will take a little while to convert each model. Stable diffusion v1.4 is about 6GB, v1.5 is at least 10GB or so.
If you want to use inpainting, you will need a second model trained for that purpose:
# on linux:
> python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="runwayml/stable-diffusion-inpainting" --output_path="./models/stable-diffusion-inpainting"
# on windows:
> python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="runwayml/stable-diffusion-inpainting" --output_path=".\models\stable-diffusion-inpainting"
Test the models
You should verify that all of the steps up to this point have worked correctly by attempting to run the
api/test-setup.py script, which is a slight variation on the original txt2img script.
If the script works, there will be an image of an astronaut in outputs/test.png.
If you get any errors, check the known errors section.
Upscaling and face correction
Models:
- https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth
- https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth
Usage
Running the containers
OCI images are available for both the API and GUI, ssube/onnx-web-api and ssube/onnx-web-gui, respectively. These
are regularly built from the main branch and for all tags.
The ssube/onnx-web-gui image is available in both Debian and Alpine-based versions, but the ssube/onnx-web-api
image is only available as a Debian-based image, due to this Github issue with onnxruntime.
When using the containers, make sure to mount the models/ and outputs/ directories. The models directory can be
read-only, but outputs should be read-write.
> podman run -p 5000:5000 --rm -v ../models:/models:ro -v ../outputs:/outputs:rw docker.io/ssube/onnx-web-api:main-buster
> podman run -p 8000:80 --rm docker.io/ssube/onnx-web-gui:main-nginx-bullseye
Configuring and running the server
The server relies mostly on two paths, the models and outputs. It will make sure both paths exist when it starts up, and will exit with an error if the models path does not.
Both of those paths exist in the git repository, with placeholder files to make sure they exist. You should not have to
create them, if you are using the default settings. You can customize the paths by setting ONNX_WEB_MODEL_PATH and
ONNX_WEB_OUTPUT_PATH, if your models exist somewhere else or you want output written to another disk, for example.
In the api/ directory, run the server with Flask:
> flask --app=onnx_web.serve run
Note the IP address this prints.
If you want to access the server from other machines on your local network, pass the --host argument:
> flask --app=onnx_web.serve run --host=0.0.0.0
This will listen for requests from your current local network and may be dangerous.
You can stop the server by pressing Ctrl+C.
Securing the server
When making the server publicly visible, make sure to use appropriately restrictive firewall rules along with it, and consider using a web application firewall to help prevent malicious requests.
Updating the server
Make sure to update your server occasionally. New features in the GUI may not be available on older servers, leading to options being ignored or menus not loading correctly.
To update the server, make sure you are on the main branch and pull the latest version from Github:
> git branch
* main
> git pull
If you want to run a specific tag of the server, run git checkout v0.4.0 with the desired tag.
Building the client
If you plan on building the GUI bundle, instead of using a hosted version like on Github Pages, you will also need to install NodeJS 18:
If you are using Windows and Git Bash, you may not have make installed. You can add some of the missing tools from the ezwinports project and others.
From within the gui/ directory, edit the gui/examples/config.json file so that api.root matches the URL printed
out by the flask run command you ran earlier. It should look something like this:
{
"api": {
"root": "http://127.0.0.1:5000"
}
}
Still in the gui/ directory, build the UI bundle and run the dev server with Node:
> npm install -g yarn # update the package manager
> make bundle
> node serve.js
Hosting the client
You should be able to access the web interface at http://127.0.0.1:3000/index.html or your local machine's hostname.
- If you get a
Connection Refusederror, make sure you are using the correct address and the dev server is still running. - If you get a
File not founderror, make sure you have built the UI bundle (make bundle) and are using the/index.htmlpath
The txt2img tab will be active by default, with an example prompt. When you press the Generate button, an image should
appear on the page 10-15 seconds later (depending on your GPU and other hardware). Generating images on CPU will take
substantially longer, at least 2-3 minutes. The last four images will be shown, along with the parameters used to
generate them.
Customizing the client config
You can customize the config file if you want to change the default model, platform (hardware acceleration), scheduler, and prompt. If you have a good base prompt or always want to use the CPU fallback, you can set that in the config file:
{
"default": {
"model": "stable-diffusion-onnx-v1-5",
"platform": "amd",
"scheduler": "euler-a",
"prompt": "an astronaut eating a hamburger"
}
}
When running the dev server, node serve.js, the config file will be loaded from out/config.json. If you want to load
a different config file, save it to your home directory named onnx-web-config.json and copy it into the output
directory after building the bundle:
> make bundle && cp -v ~/onnx-web-config.json out/config.json
When running the container, the config will be loaded from /usr/share/nginx/html/config.json and you can mount a
custom config using:
> podman run -p 8000:80 --rm -v ~/onnx-web-config.json:/usr/share/nginx/html/config.json:ro docker.io/ssube/onnx-web-gui:main-nginx-bullseye
Known errors and solutions
Error: name 'cmd' is not definedwhile setting up the virtual environment:- install venv through apt:
sudo apt install python3-venv - see https://www.mail-archive.com/debian-bugs-dist@lists.debian.org/msg1884072.html
- install venv through apt:
- command not found
pythonorpip:- some systems differentiate between Python 2 and 3, and reserve the
pythoncommand for 2
- some systems differentiate between Python 2 and 3, and reserve the
- connection refused:
- make sure the API and GUI are both running
- make sure you are using the correct hostname or IP address
- open the appropriate firewall ports:
- TCP/5000 for the API dev server
- TCP/3000 for the GUI dev server
- TCP/80 for the GUI using nginx without a container
- TCP/8000 for the GUI using the nginx container
- CUDA errors:
- make sure you are using CUDA 11.x
- https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements
- numpy invalid combination of arguments:
- make sure to export ONNX models using the same packages and versions that you use while running the API
- numpy
np.floatmissing- reinstall
pip install "numpy>=1.20,<1.24 --force-reinstall" - another package may have upgraded numpy to 1.24, which removed that symbol
- reinstall