|
|
||
|---|---|---|
| .vscode | ||
| api | ||
| common | ||
| docs | ||
| gui | ||
| models | ||
| outputs | ||
| .gitignore | ||
| .gitlab-ci.yml | ||
| CHANGELOG.md | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| onnx-web.code-workspace | ||
| renovate.json | ||
README.md
ONNX Web
This is a rudimentary web UI for ONNX models, providing a way to run GPU-accelerated models on Windows and even AMD with a remote web interface.
This is still fairly early and instructions are a little rough, but it works on my machine. If I keep working on this for more than a week, I would like to add img2img and Nvidia support.
Based on guides by:
- https://gist.github.com/harishanand95/75f4515e6187a6aa3261af6ac6f61269
- https://gist.github.com/averad/256c507baa3dcc9464203dc14610d674
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
- https://www.travelneil.com/stable-diffusion-updates.html
Features
- REST API server capable of running ONNX models with DirectML acceleration
- AMD hardware acceleration
- CPU software fallback
- multiple schedulers
- web app to generate and view images
- can be hosted alongside API or on a CDN
- built with React and MUI
- txt2img mode
- outputs are saved to file
- show image history
Contents
Setup
This is a very similar process to what harishanand95 and averad's gists recommend, split up into a few steps:
- Install Git and Python, if you have not already
- Create a virtual environment
- Install pip packages
- Install ORT Nightly package
- Download and convert models
Note about setup paths
This project contains both Javascript and Python, for the client and server respectively. Make sure you are in the correct directory when working with each part.
Most of these setup commands should be run in the Python environment and the api/ directory:
> cd api
> pwd
/home/ssube/code/github/ssube/onnx-web/api
The Python virtual environment will be created within the api/ directory.
The Javascript client can be built and run within the gui/ directory.
Install Git and Python
Install Git and Python 3.10 for your environment:
The latest version of git should be fine. Python must be 3.10 or earlier, 3.10 seems to work well. If you already have Python installed for another form of Stable Diffusion, that should work, but make sure to verify the version in the next step.
Create a virtual environment
Make sure you have Python 3.10 or earlier, then create a virtual environment:
> python --version
Python 3.10
> pip install virtualenv
> python -m venv onnx_env
This will contain all of the pip libraries. If you update or reinstall Python, you will need to recreate the virtual environment.
Every time you start using ONNX web, activate the virtual environment:
# on linux:
> source ./onnx_env/bin/activate
# on windows:
> .\onnx_env\Scripts\Activate.bat
Update pip itself:
> python -m pip install --upgrade pip
Install pip packages
Install the following packages for AI:
> pip install numpy>=1.20,<1.24 # version is important, 1.24 removed the deprecated np.float symbol
> pip install accelerate diffusers transformers ftfy spacy scipy
> pip install onnx onnxruntime torch
# TODO: is pytorch needed?
If you are running on Windows, install the DirectML ONNX runtime as well:
> pip install onnxruntime-directml --force-reinstall
Install the following packages for the web UI:
> pip install flask stringcase
Or install all of these packages at once using the requirements.txt file:
> pip install -r requirements.txt
At the moment, only numpy seems to need a specific version. If you see an error about np.float, make sure you are
not using numpy>=1.24. This SO question
has more details.
I got a warning about an incompatibility in protobuf when installing the onnxruntime-directml package, but have not seen any issues. Some of the gist guides recommend diffusers=0.3.0, but I had trouble with old versions of diffusers
before 0.6.0 or so. If I can determine a good set of working versions, I will pin them in requirements.txt.
Install ORT nightly package
Download the latest DirectML ORT nightly package for your version of Python and install it with pip.
Downloads can be found at https://aiinfra.visualstudio.com/PublicPackages/_artifacts/feed/ORT-Nightly. If you are using
Python 3.10, download the cp310 package. For Python 3.9, download the cp39 package, and so on.
> pip install ~/Downloads/ort_nightly_directml-1.14.0.dev20221214001-cp310-cp310-win_amd64.whl --force-reinstall
Make sure to include the --force-reinstall flag, since it requires some older versions of other packages, and will
overwrite the versions you currently have installed.
Download and convert models
Sign up for an account at https://huggingface.co and find the models you want to use. Popular options include:
Log into the HuggingFace CLI:
> huggingface-cli.exe login
Issue an API token from https://huggingface.co/settings/tokens, naming it something memorable like onnx-web, and then
paste it into the prompt.
Download the conversion script from the huggingface/diffusers repository to the root of this project:
Run the conversion script with your desired model(s):
> python convert_stable_diffusion_checkpoint_to_onnx.py \
--model_path="runwayml/stable-diffusion-v1-5" \
--output_path="./models/stable-diffusion-onnx-v1-5"
This will take a little while to convert each model. Stable diffusion v1.4 is about 6GB, v1.5 is at least 10GB or so.
You can verify that all of the steps up to this point worked correctly by attempting to run the api/setup-test.py
script, which is a slight variation on the original txt2img script.
Usage
Configuring and running the server
The server relies mostly on two paths, the models and outputs. It will make sure both paths exist when it starts up, and will exit with an error if the models path does not.
Both of those paths exist in the git repository, with placeholder files to make sure they exist. You should not have to
create them, if you are using the default settings. You can customize the paths by setting ONNX_WEB_MODEL_PATH and
ONNX_WEB_OUTPUT_PATH, if your models exist somewhere else or you want output written to another disk, for example.
In the api/ directory, run the server with Flask:
> flask --app=onnx_web.serve run
Note the IP address this prints.
If you want to access the server from other machines on your local network, pass the --host argument:
> flask --app=onnx_web.serve run --host=0.0.0.0
This will listen for requests from your current local network and may be dangerous.
Securing the server
When making the server publicly visible, make sure to use appropriately restrictive firewall rules along with it, and consider using a web application firewall to help prevent malicious requests.
Configuring and hosting the client
From within the gui/ directory, edit the gui/examples/config.json file so that api.root is the URL printed out by
the flask run command from earlier. It should look something like this:
{
"api": {
"root": "http://127.0.0.1:5000"
}
}
Still in the gui/ directory, build the UI bundle and run the dev server with Node:
> make bundle
> node serve.js
Using the web interface
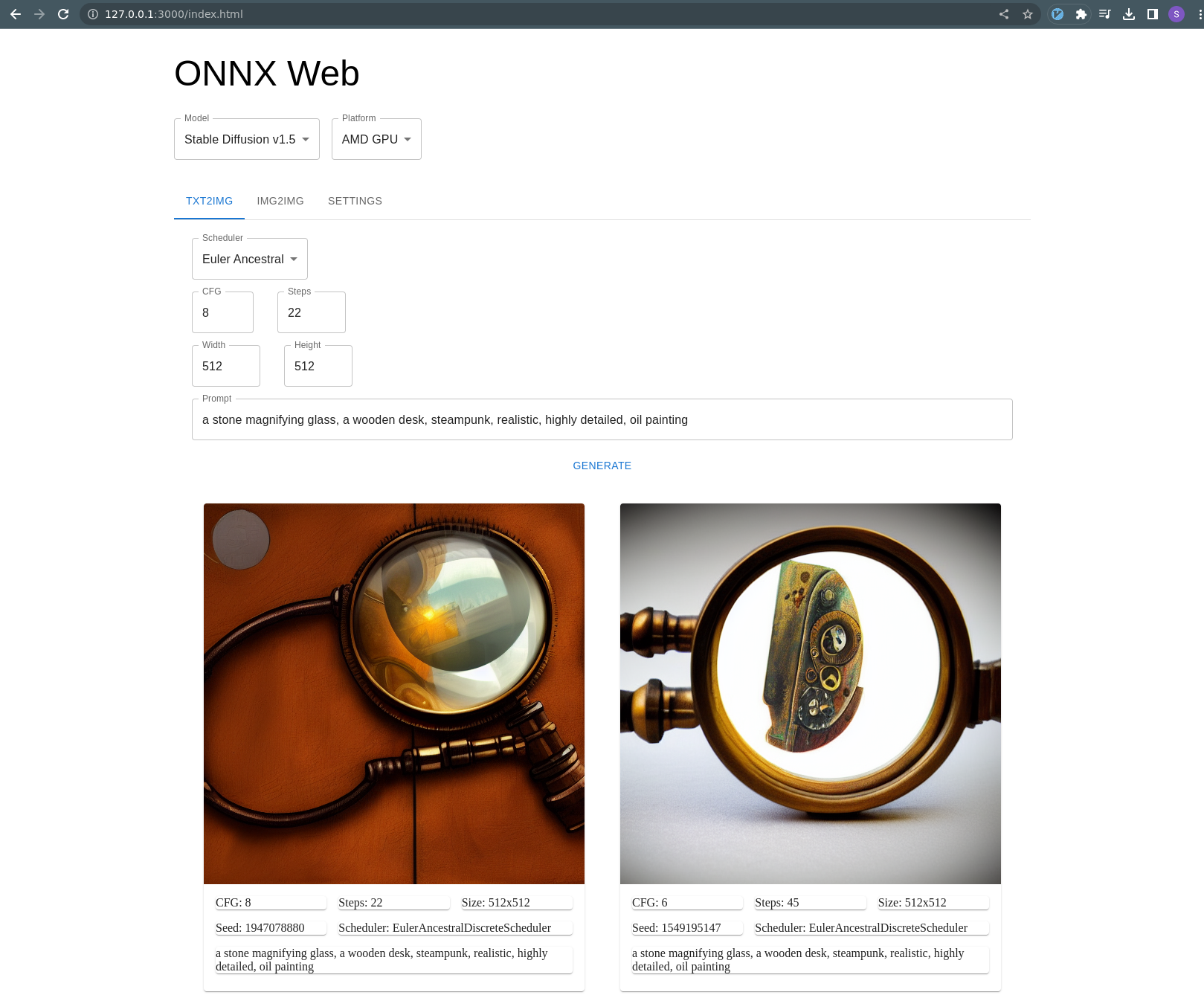
You should be able to access the web interface at http://127.0.0.1:3000/index.html or your local machine's hostname.
- If you get a
Connection Refusederror, make sure you are using the correct address and the dev server is still running. - If you get a
File not founderror, make sure you have built the UI bundle (make bundle) and are using the/index.htmlpath
The txt2img tab will be active by default, with an example prompt. You can press the Generate button and an image
should appear on the page 10-15 seconds later (depending on your GPU and other hardware). The last four images will
be shown, along with the parameters used to generate them.
Running from containers
OCI images are available for both the API and GUI, ssube/onnx-web-api and ssube/onnx-web-gui, respectively. These
are regularly built from the main branch and for all tags.
The ssube/onnx-web-gui image is available in both Debian and Alpine-based versions, but the ssube/onnx-web-api
image is only available as a Debian-based image, due to this Github issue with onnxruntime.
When using the containers, make sure to mount the models/ and outputs/ directories. The models directory can be
read-only, but outputs should be read-write.
> podman run -p 5000:5000 --rm -v ../models:/models:ro -v ../outputs:/outputs:rw docker.io/ssube/onnx-web-api:main-buster
> podman run -p 8000:80 --rm docker.io/ssube/onnx-web-gui:main-nginx-bullseye
Customizing the config
You can customize the config file to change the default model, platform (hardware acceleration), scheduler, and prompt. If you have a good base or example prompt, you can set that in the config file:
{
"default": {
"model": "stable-diffusion-onnx-v1-5",
"platform": "amd",
"scheduler": "euler-a",
"prompt": "an astronaut eating a hamburger"
}
}
When running the dev server, node serve.js, the config file will be loaded from out/config.json. If you want to load
a different config file, save it to your home directory named onnx-web-config.json and copy it into the output
directory after building the bundle:
> make bundle && cp -v ~/onnx-web-config.json out/config.json
When running the container, the config will be loaded from /usr/share/nginx/html/config.json and you can mount a
custom config using:
> podman run -p 8000:80 --rm -v ~/onnx-web-config.json:/usr/share/nginx/html/config.json:ro docker.io/ssube/onnx-web-gui:main-nginx-bullseye